
The current trend for many application requiring data converters is to get closer and closer to a full SDR (Software Defined Radio) system. While SDR architecture brings many benefits in terms of flexibility and SWaP-C (Size, Weight, Power and Cost) it often translates into higher bandwidth capability and is directly linked to the data converter sampling speed with the Shannon-Nyquist theorem. And this complicates the interface between FPGA (Field Programmable Gate Array) and data converter. Indeed the speed at which FPGA process information is very limited compared to the amount of data generated by high-speed data converter. Of course, this is dealt through massive parallel processing. However transmitting and receiving this huge amount of data has become the system bottleneck as data needs to be transmitted in larger and larger quantities, faster and faster. This paper covers and compares the two means of interfacing at high-speed between FPGA and data converter currently used today: high-speed LVDS parallel interface and high-speed serial interface. It considers multiple aspects ranging from RF with trace length and signal integrity to the system level with cost and ease of development. It starts by introducing these 2 types of interfaces, comparing them and identifying their benefits and drawbacks. Then it discusses the FPGA design of a high-speed parallel interface at 1.5Gbps. It focuses on a transmission from an FPGA to a DAC (Digital to Analog Converter) using the example of an Arria V FPGA from Altera interfacing with an EV12DS460A from e2v. Before concluding, it covers a high-speed serial interface FPGA design at 6Gbps using the ESIstream (Efficient Serial Interface) protocol. It focuses on a transmission from an ADC (Analog to Digital Converter) to an FPGA using the example of an EV12AD500A from e2v interfacing with a Virtex 7 from Xilinx.
The use of high-speed data converters is vastly increasing as more and more applications are looking toward them as a solution to improve by an order of magnitude, the performance and capabilities of their system; from communication (ground and satellite based) to high-energy physics (accelerator, synchrotron) application, including defence (electronic warfare, radar, radar jamming), industrial (cellphone test line, tank container monitoring), test and measurement (oscilloscope, spectrum analyzer, mass spectrometer), and earth observation (synthetic aperture radar) applications. Each of these application domains brings its own constraints and requirements among which is the choice of interface at these high-speed. The traditional way of interfacing with a data converter has been using a parallel interface as it is straight forward in terms of PCB and firmware design – each bit of the sample has its own path. However, at high-speed – above 1 GHz –, many parameters negligible at lower speed, start to limit the performance of the interface. Thus serial interface options have started to appear about 10 years ago and are now preferred in most of the applications. This paper aims at explaining how both interfaces work through a comparison of their benefits and drawbacks followed by two examples, one of each interface solution.
Comparison of parallel and serial interface
A parallel interface is defined simply as an interface using a certain number of lanes to transmit data plus a lane to transmit the clock between transmitter (TX) and receiver (RX) as can be seen in Figure 1.a; and a serial interface, as an interface using a certain number of lanes to transmit encoded data between TX and RX through high-speed transceivers comprising a serializer on the TX side and its counterpart, a deserializer, on the RX side as shown in Figure 1.b.

Figure 1: (a): Schema of a parallel interface; (b): Schema of a serial interface
A few differences can be noted from the definition of these two types of interface:
- The clock signal is not transmitted for the serial interface. Indeed, it is not transmitted directly but recovered on the RX side through a CDR (Clock and Data Recovery) system which brings a few advantages mentioned later in this paper;
- For the serial interface an encoding/decoding of the data is mandatory. It should be noted that encoding/decoding can be applied and useful in the case of parallel interface but is not mandatory for it to function. While for a serial interface, not having encoding/decoding results in BER (Bit Error Rate) loss for the transmission due to multiple effects introduced later in this paper.
Historically, parallel interface used to be the only solution available due to its easiness and direct implementation approach. With each digital clock cycle a bit value is transmitted on a lane. And the RX having access to the clock signal it recovers the data easily. This is true at low data rate, but when the data rate starts increasing, many difficulties add complexity to developing such an interface. To satisfy the increasing demand for bandwidth, the parallel interface solution is quickly limited in terms of data rate per lane and left only with the option of increasing the number of lanes to increase the bandwidth. Today parallel interface is being, in most cases, replaced by serial interface because of the bandwidth capabilities such interface allows reaching. A simple comparison of the data rate achievable for these two interfaces on the main FPGA manufacturers that are Xilinx and Altera/Intel show the benefit of the serial interface. Today parallel interface in FPGA are limited at 1.6Gbps; while high-speed serial transceiver can reach 32Gbps and even higher.
Looking on the digital side, it is visible that the parallel interface is a lot easier compared to the serial interface which needs encoding/decoding and the transceiver stages – even if parallel interface today offer some of these functions as well to improve performance. This translates into a huge latency advantage for the parallel interface which makes it vital for application like electronic warfare where a few nanoseconds can be the difference between being spotted or remaining invisible to enemies’ radar system. These stages used for the serial interface means that it also requires more resources from the FPGA (LUT and FIFO or elastic buffer). It is generally small enough not to be an issue but could complicate the closing of the timing within the FPGA when the application requires a large quantity of resources or high-speed digital design.
In terms of RF consideration, high-speed serial interface, running faster, need more care. Following the Shannon-Nyquist theorem, a transmission at Gbps contains frequency up to  . The insertion loss of a medium over the frequency band from DC to is not flat. It can be assimilated to a low pass order with a response depending on and the transmission medium used. If the overall attenuation at high frequency is too high, bit would be seen wrongly by the reception stage. This relates to the Inter-Symbol Interference (ISI) effect. Solution built in the transceiver exists to cope with this effect: emphasis and equalization but careful PCB layout on the fast serial lane helps.
. The insertion loss of a medium over the frequency band from DC to is not flat. It can be assimilated to a low pass order with a response depending on and the transmission medium used. If the overall attenuation at high frequency is too high, bit would be seen wrongly by the reception stage. This relates to the Inter-Symbol Interference (ISI) effect. Solution built in the transceiver exists to cope with this effect: emphasis and equalization but careful PCB layout on the fast serial lane helps.
Considering the timing, a few factors need to be taken into account. First of all timing uncertainties are the limiting factor for parallel interface speed. When timing uncertainties are small enough compared to the data period minus the meta-stable zone (setup and hold time) at the RX input, it is possible to configure a parallel interface – this relates to the opening of the eye at the RX input. Equation (1) below shows this relation when using an SDR (Single Data Rate) interface and equation (2) when using a DDR (Double Data Rate) interface:

With 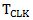 the clock period;
the clock period;  the input setup time;
the input setup time;  the input hold time;
the input hold time; 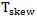 the packages, PCB and bit to bit skews;
the packages, PCB and bit to bit skews;  the clock and data jitter;
the clock and data jitter;  the PVT (Process- Voltage- Temperature) variations;
the PVT (Process- Voltage- Temperature) variations;  the rise and fall time of the data and
the rise and fall time of the data and  the clock duty cycle distortion. This induces a few constraints to respect. Firstly, the bit to bit skew should be reduced as much as possible; this can be done either by matching the PCB trace length of the data and/or adding controlled delay independently for each bit lanes. Secondly, the alignment between the clock and the data at the RX input needs to be controlled to avoid the data to arrive within the meta-stability zone. This can be achieved either by delaying the clock or the data compared to the other. The timing aspect is where the main complexity comes from for high-speed parallel interface; and it is limiting the maximum speed achievable.
the clock duty cycle distortion. This induces a few constraints to respect. Firstly, the bit to bit skew should be reduced as much as possible; this can be done either by matching the PCB trace length of the data and/or adding controlled delay independently for each bit lanes. Secondly, the alignment between the clock and the data at the RX input needs to be controlled to avoid the data to arrive within the meta-stability zone. This can be achieved either by delaying the clock or the data compared to the other. The timing aspect is where the main complexity comes from for high-speed parallel interface; and it is limiting the maximum speed achievable.
On the other hand, a high-speed serial interface RX recovers the clock from the data stream – using the CDR. This means that the clock recovered has had the same timing effect as the data up to the CDR stage. Thus the timing effect on the data and the clock cancels each other allowing much faster speed. This is a simple way of translating the benefit of the serial interface and CDR; for more detailed information multiple articles, paper and presentation are available and discuss the CDR benefits, architecture and function. And increasing the data rate per lanes allows sending the same amount of data in a smaller number of lanes saving PCB real estate and easing PCB layout. The protocol is also used to align digitally multiple serial lanes together which mean that there is no need to match the trace lengths for a serial interface.
Finally at system level, high-speed transceivers are more costly resources. Even if their wide adoption has allowed a price decrease, system targeting low cost will prefer working with parallel interface or slow serial interface.
To conclude this section, nowadays, serial interface is the interface of choice in most of the application thanks to the benefits it brings in term of bandwidth capabilities but parallel interface are still necessary and used for latency constrained application. Low cost or low speed application could consider both solutions depending on different factors like development time, reuse of already developed sub-system and other application requirements.
Example of parallel interface between FPGA and DAC
A. System overview
This example of a parallel interface is based on the evaluation board or the EV12DS460A. It is composed of the EV12DS460A, a 12 bits, 6GSps DAC [1] and the Arria V from Altera/Intel [2]. The Figure 2 below show a block diagram of the system.

Figure 2: Block diagram of the FPGA-DAC interface
In this example, the FPGA corresponds to the TX and the DAC is the RX. The blue path corresponds to the data path from the FPGA to the DAC conversion core. The green path is the clock network. And the red part concerns the control and settings. Due to the high sampling speed of the DAC at 6GSps, 4 input ports (Port A to D in Figure 2) at 1.5Gbps are used to interface with the FPGA and an internal mux (MUX 4:1) provides the data to the conversion core at 6GSps.
To prevent meta-stability issue at the DAC input a solution is implemented with a detection/correction loop. First of all, the fast clock is provided to the DAC (CLK), it is then divided by 4 internally to the DAC (DIV /4) and goes through a digitally controlled delay (τ) controlled through the PSS setting. The output of the digitally controlled delay (DSP) is transmitted to the FPGA clock system (PLL) which then generates the clock used to output the data from the FPGA. At the input of the DAC, a detection system is continuously checking if there is a meta-stability issue which is indicated through the TVF bit to the FPGA. Upon such detection, the FPGA CONTROL resets the PSS bit to change the delay between data at the DAC input and the clock that recovers them. This method is used to identify where the meta-stability is and help setting the interface.