
One of the fun things to do while at DesignCon is discuss war stories with fellow engineers. While chatting with Eric Bogatin after another great panel discussion, he requested I capture some of my war stories in writing.
I still remember the first time I met Eric at PCB East (many years ago), and he was performing a demo of what would eventually be ANSOFT Full Wave field solver (but that’s another story). After a little brainstorming, I came up with an entire list of great SI/PI lessons that I have toiled through and would love to share with the community. Anyway, with Eric’s encouragement I decided to capture one recent war story I troubleshot. Hopefully, I will be able to present other SI lessons to document and share my experiences.
It is not uncommon in the early development of an Ethernet Switch for a prototype switch to exhibit what is known as a “link flap.” This is where a link, typically 10G SFP+ on the front or back faceplate, will go down then back up in a very brief period of time. It can usually be easily root caused to some software or hardware bug in the early stages of the design cycle.
Every network engineer’s nightmare is when you hear from your local GTAC (Global Technical Assistance Center) engineer that it is happening in the field on a product already shipping. In the picture directly below, I was able to reproduce in our RF chamber what nobody else was able to reproduce. What was really interesting was the placement of Books (SI books to be specific) on this random sample (not shown because it is under the books) affected the behavior.

For some time there was what appeared to be random failures out in the field where a remote switch tied through SFP+ stacking ports to a local switch would link flap, which means that the link would repeatedly go up and down. It was observed at multiple sites, across multiple customers, but was relatively rare when considering the number of switches deployed in the field. I have come to find that you must use all of the tools and intuition available at your disposal as well as digging into problem description and history, customer logs, then perform simulations and measurements.
Once a problem is locally reproducible you can examine the usual suspects: software, hardware, layout, mechanical, power, clocks, and the channel. Reproducing the problem is often 90 % of finding a solution.
So, in the case of the link flap, I reviewed all of the DVT data and documentation on this problem past and present. I repeated a number of measurements myself (clocks, power, and channel) and did not initially observe anything suspicious. I reviewed the layout with a fresh set of eyes. What was interesting about this problem was early on some switches were root caused to an MDI clock issue, but once fixed, a few customer problems remained.
There was one particularly interesting problematic site in Europe, where they had the 2 switch setup (local and remote) on a cart with isolated power. They found if they rolled the cart into the computer room, the remote switch would flap, while the local switch did not exhibit any flapping.
We sent a few really sharp engineers over to this friendly customer and they spent a week trying to debug the issue on site where the problem was easily reproduced. At the end of the week they were no closer to understanding the problem. They thought it might be EMI/RFI related but were not sure because the problem seemed to come and go depending on where the rack of equipment was wheeled to. They also examined possibilities of power and grounding issues. This European site typically runs the switches at high line (240V, versus the 120V).
When they returned empty handed I took it upon myself to try and figure out what was going on. I headed down to the RF chamber with three switches, laptops and a scope to see if I could reproduce the problem there. Like Einstein said, genius is 1% talent and 99 % hard work. I think this is also the case of debugging a long outstanding problem. I thus started my month long quest to debug an issue that was long outstanding and had significant visibility.
EMI/RFI guys also discovered a method to induce repeatable link flap. EFT burst applied to the protective earth on the power supply at a voltage of 2.1 kV results in remote link flap. I subsequently created remote link flap with my EFT generator at a relatively low value of ~ .38 Kva.

Console log
<Info:vlan.msgs.portLinkStateDown> Port 25 link down
<Info:vlan.msgs.portLinkStateUp> Port 25 link UP at speed 10 Gbps
<Info:vlan.msgs.portLinkStateDown> Port 25 link down
<Info:vlan.msgs.portLinkStateUp> Port 25 link UP at speed 10 Gbps
<Info:vlan.msgs.portLinkStateDown> Port 25 link down
<Info:vlan.msgs.portLinkStateUp> Port 25 link UP at speed 10 Gbps
<Info:vlan.msgs.portLinkStateDown> Port 25 link down
Moving my setup into the RF chamber, I had two switches (DUT and BASELINE) rear panel SFP+ ports linked to the front panel of a remote switch (customer configuration). Both baseline and DUT units were in the test chamber, while the remote switch was outside the chamber. I was working with two random samples I pulled out of engineering, not customer RMAs.
After days of testing I started experimenting with opening and closing the RF chamber door, and suddenly I started to notice link flaps. They would happen for a short period then stop. So, we then experimented with air flow, sheet metal on/off/pressure. It was only reproducible when the RF chamber door was opened/closed.
After leaving the door open overnight, I noticed the next morning specific time periods over the previous night the switch flapped, then a large delay, then it would flap again. I felt like Christopher Columbus bumping into the new world. No one was able to reproduce the problem, now I had reproduced it.
All of a sudden it hit me. The engineers stated the environment in the computer room over in Europe was cold. The heat gets turned down (in our building) at night. I grabbed a thermometer and placed it next to the switch and recorded the temperatures overnight. Sure enough, at night they cycle heat off and one remote switch would flap repeatable when it passed through a specific temperature ~ 13.6 Degrees C.
I wanted to debug why the remote switch flapped but the local one did not. What we uncovered was that the PHY was issuing remote fault status errors, but local fault registers were not getting set. So whatever the failure mechanism, it was local to the PHY. As a workaround, we found that disabling the remote fault status indicator prevented link bounce but caused packet loss and CRCs. I inspected the motherboard, daughter board (VIM), connectors and layout again to look for any signs of mechanical damage. None were found (see figure below of connector showing no signs of damage).

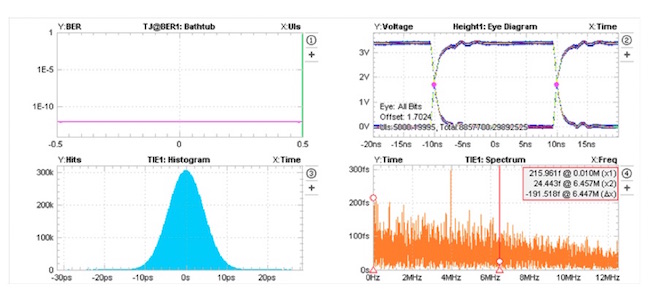
I next moved the local switch from the RF chamber into the heat chamber to determine exact failing temperature. It ended up being a very narrow band ~ 13.3 degrees C when the switch was passed through that temperature. Now we were able to isolate it to a temperature issue, it was time to root cause to a component. We swept the chamber up and down through the narrow temperature band while fixturing up a scope. After a relatively short time I isolated the failure to jitter on the 25MHz oscillator. Replacing the $.50 oscillator with a higher grade $2.00 oscillator (of the same footprint) eliminated the issue.
New Oscillator phase Noise min/max= 2.5ps -> 3.1ps (overnight- 12898 samples)
Old Oscillator phase Noise min/max = 6.9ps -> 8.5ps (~ 1hour - population 333 samples)
PHY Spec is 3 ps-rms (12KHz – 5Mhz)
The image below shows the jitter of the old oscialltor (over a lunch break):

This image shows the jitter of the new oscillator over night:
This story actually foreshadows the next one I plan on writing, when a really smart chip designer came on site to help us debug a nasty problem and was almost stumped. The very first thing he did was swap out the crystal oscillator with a very high performance PLL based oscillator. It turned out that this was not the problem, but oscillators are always a good place to start when debugging problems.
Robert Haller, Senior Principal Hardware Engineer for Extreme Networks, is working on next generation Ethernet switching solutions, is the corporate Signal and Power Integrity lead and has been a member of the DesignCon Technical Program Committee for 17 years.